What's the difference between a "language model" and a "large language model"?
A "Large Language Model" (LLM) is a type of "Language Model" (LM) with more parameters, which allows it to generate or understand text better. The term 'large' refers to the number of parameters the model has been trained on. Usually, a LLM provides higher quality results than smaller LMs due to its ability to capture more complex patterns in the data.
What do these numbers mean in the names of models?
For example: "Vicuna-13B". The name of the model is Vicuna, and it has 13 billion parameters.
What is a parameter?
A parameter is a value that the model learns during training. These values are adjusted through a process called backpropagation, which involves calculating the error between the model's predictions and the actual output and adjusting the parameters to minimize this error. The number of parameters in an LLM is typically very large, often numbering in the millions or even billions. These parameters capture the relationships between different words and phrases in language, allowing the model to generate human-like output and make accurate predictions. Without these parameters, a language model would not be able to perform natural language processing tasks at a high level of accuracy.
What does “training” an ML model mean?
Training a model involves exposing it to large amounts of data so that it can learn patterns and make accurate predictions. During training, the parameters of the model are adjusted based on the input data and desired output. This process can take a significant amount of time and computational resources, but it is essential for achieving high levels of accuracy in natural language processing tasks.
How does a typical training run work?
During a typical training run, the language model is fed with a large amount of text data and corresponding targets. Generally, the targets are “masked” words within a training sequence that the model needs to predict. The model then uses its prediction errors as compared against these inputs to repeatedly update its parameters through an optimization algorithm like stochastic gradient descent (SGD) or Adam.
During training, the network makes predictions on a batch of input data and calculates the loss, which is a measure of how well the predictions match the actual targets. The optimizer then adjusts the weights of the network using backpropagation to minimize the loss. This process is repeated iteratively for a fixed number of epochs or until a convergence criterion is met. The process of updating the model's parameters continues iteratively until the model reaches a satisfactory level of accuracy on the training set.
It's worth noting that training a language model (especially a LLM) can be a resource-intensive process, requiring significant computational power and time.
What is backpropagation?
Backpropagation is a process used to adjust the parameters of a model during training. It involves calculating the error between the model's predictions and the actual output and adjusting the parameters to minimize this error.
The process starts by making a forward pass through the neural network, where input data is fed into the model, and output predictions are generated. The difference between the predicted output and the actual targets is then calculated using a loss function. This loss value is then backpropagated through the network, starting from the last layer and moving backward towards the first layer.
As it moves backward, each layer updates its weights based on how much it contributed to the final loss value. This process continues until all layers have updated their weights, resulting in a new set of parameters that hopefully improve the model's performance on future inputs.
What does “fine-tuning” a language model mean?
Fine-tuning a language model involves taking a pre-trained language model and providing additional training using task-specific data sets moderated by humans. This process typically requires less data than training a model from scratch and can be done relatively quickly. Fine-tuning has become increasingly popular in recent years as more pre-trained models have become available.
“RLHF” approach
The "Reinforcement Learning From Human Feedback" approach involves incorporating human feedback into machine learning models to improve their accuracy and performance. In the context of natural language processing, this might involve having humans review text generated by a model and provide feedback on its quality, which can then be used to fine-tune the model. This approach is valuable because it can be used to reduce bias and errors and make usage of AI more trustworthy.
What does "inference" mean?
Inference refers to the process of using a trained machine learning model to make predictions or decisions based on new input data. In other words, it's the application of a trained model to real-world data in order to obtain useful insights or take action based on those insights. When performing inference with a language model, the model takes in new text as input and generates output text based on what it has learned during training and fine-tuning. Inference is a critical step in the machine learning workflow, as it allows models to be used for practical applications such as chatbots, language translation, and sentiment analysis.
Is inference computationally expensive?
YES, especially for larger models with more parameters. To address this, some models use techniques such as Beam search or sampling to generate output text more efficiently. Additionally, some cloud providers offer pre-trained language models that can be accessed via APIs for a fee, which can help reduce the computational burden of running them locally.
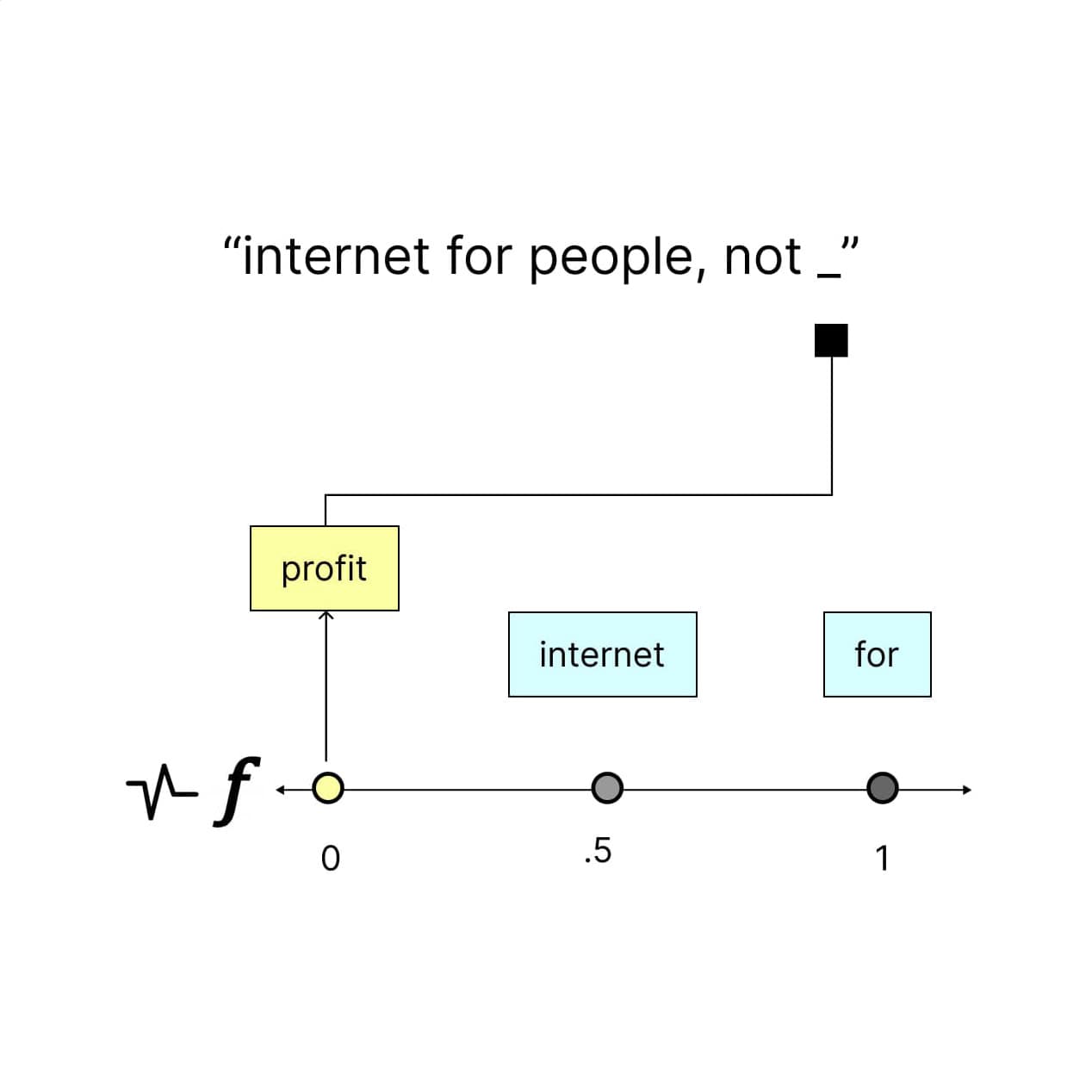
What is a vector?
In the context of natural language processing, a vector is a list of numbers used to represent a word or phrase in a way that captures its relationship to other words or phrases within a model. A key useful feature of these vectors is that similar things cluster together.
Each vector in a model consists of the same list length, with every position in the list representing a semantically interesting feature discovered about the word or phrase through statistical analysis. While it's typically difficult to explain what these individual features might mean to a human, quantifying them allows vectors to be mathematically compared as coordinates in a high-dimensional space. In such a space, distance can approximate overall similarity in meaning between the words or phrases from which the vectors were derived.
Vectors are typically derived using techniques such as word embeddings, which maps each word to a high-dimensional vector based on its co-occurrence with other words in a large corpus of text.
What is Beam search?
Beam search is a search algorithm used to generate output sequences from a model during inference. It works by maintaining a set of the top k most likely sequences at each step of the generation process, where k is known as the Beam width. The algorithm then continues generating new tokens for each sequence in the set until all sequences have reached an end-of-sequence token or a maximum length has been reached. At each step, the set of possible sequences is pruned based on their likelihood according to the model's predictions, resulting in a final set of top-k output sequences.
What is frequency?
Frequency is a parameter used in language models to control how often a token can be repeated in the generated output. It works by penalizing the model for repeating tokens that have already been used, preventing the model from generating repetitive or nonsensical text. The higher this is set, the more that repetition of tokens present in the context will be penalized in suggestions.
What is temperature?
Temperature is a technique used in language models to control the level of randomness and creativity in the generated output during inference. It works by scaling the predicted probability distribution over possible tokens at each step by a temperature parameter, which controls how much the probabilities are 'softened' or spread out.
Lower temperatures result in more conservative and predictable output, while higher temperatures lead to more diverse and creative output. However, setting the temperature too high can also lead to nonsensical or ungrammatical sentences. Finding the optimal temperature for a given task or application often requires experimentation and fine-tuning.
What is sampling?
Sampling is another algorithm used to generate output sequences from a model during inference. Unlike Beam search, which generates only the top-k most likely sequences at each step, sampling generates output tokens probabilistically based on the model's predicted probability distribution over all possible tokens at that step. This can lead to more diverse and creative output compared to Beam search, but it can also result in less coherent or grammatical sentences if not properly controlled through techniques such as temperature scaling or nucleus sampling.
What is 'top_k' sampling?
Top-k sampling is a method used in language generation where, instead of considering all possible next words in the vocabulary, the model only considers the top 'k' most probable next words.
This technique helps to focus the model on likely continuations and reduces the chances of generating irrelevant or nonsensical text. It strikes a balance between creativity and coherence by limiting the pool of next word choices, but not so much that the output becomes deterministic.
What is 'top_p' sampling?
Top-p sampling, also known as nucleus sampling, is a strategy where the model considers only the smallest set of top words whose cumulative probability exceeds a threshold 'p'.
Unlike top-k which considers a fixed number of words, top-p adapts based on the distribution of probabilities for the next word. This makes it more dynamic and flexible. It helps create diverse and sensible text by allowing less probable words to be selected when the most probable ones don't add up to 'p'.