Artificial intelligence (AI), machine learning (ML), large language models (LLMs) and related technologies and techniques have crossed the chasm from science fiction and niche research domains into widespread awareness and widely adopted products, services, and systems in 2023.
Although the history of AI research reaches back to the 1950s, the current widespread awareness of AI can be traced to a recent set of products and services using generative AI such as ChatGPT, Stable Diffusion, and the like. In particular, OpenAI's ChatGPT captured the imagination of many by removing many technical barriers to interacting with AI through “natural language” text conversations. As such, ChatGPT allowed individuals to see the power, promise, and pitfalls of such systems, and many heralded the moment as a new epoch in the history of computing.
The rapid popularity of ChatGPT and other systems meant new attention and investment in the domain. Almost overnight, new applications and companies emerged that sought to make use of these technologies in new ways and new domains. As a result, a myriad of industries are finding new ways to use this technology for better decision-making, automation, and innovation.
Alongside this expansion in interest and development is the need for individuals in a variety of roles to quickly ramp up their understanding of AI. However, with the increasing complexity of these models, the substantial amount of new things to learn and the extensive list of new libraries being added every single day, onboarding into the state-of-the-art AI world has become challenging for new engineers. While resources exist, many of these resources (and increasingly so) depend on proprietary technologies. Moreover, the state of knowledge is rapidly changing, and existing resources are quickly out-of-date.
Why are people excited about LLMs?
Large Language Models (LLMs) are AI models that use deep learning techniques to process and understand natural language text. These models have millions or even billions of parameters that allow them to generate human-like language output, making them ideal for tasks such as language translation, natural-sounding chatbots, document and code generation, and more. LLMs have been trained on massive amounts of data, allowing them to identify patterns in language that were previously difficult for computers to comprehend. This has led to breakthroughs in natural language processing, generated output and improved communication between humans and machines.
Why are people concerned about LLMs?
LLMs are currently used to power chatbots and a wide variety of content tools that can generate text, images, video, and even code. But the very traits that make LLMs so powerful and useful also present important questions that technologists need to consider when developing and deploying them.
By mimicking human language and creativity, LLMs have the potential to transform or even automate certain tasks or jobs. The mass harvesting of data to train these systems presents largely unresolved challenges to the principles of copyright, fair use, and fair compensation. The tendency of users to view LLM-powered tools as “officious oracles” can lead humans to make flawed or harmful decisions based on the biases and misinformation these systems can produce. LLMs can generate high quality prose that naturally invites consumers to forget that LLMs offer no guarantees of communicating factual or accurate information.
At Mozilla, we believe that developers should take these risks seriously and cultivate both an understanding and awareness of how their chosen AI technologies behave and impact the world. By their very nature, open source LLMs offer a greater chance to achieve those goals.
What exactly is an LLM?
At its heart, a Transformer-based Large Language Model (LLM) is essentially a computer program designed to generate text that resembles human-written content. It leverages machine learning techniques, specifically a type of neural network called a Transformer. At a high-level, a Transformer encodes linguistic patterns in the form of statistical relationships between words, and then uses those patterns to generate text. Transformers encode these semantic patterns by ingesting examples of existing text. Now let’s dig a little deeper.
Here's how it works:
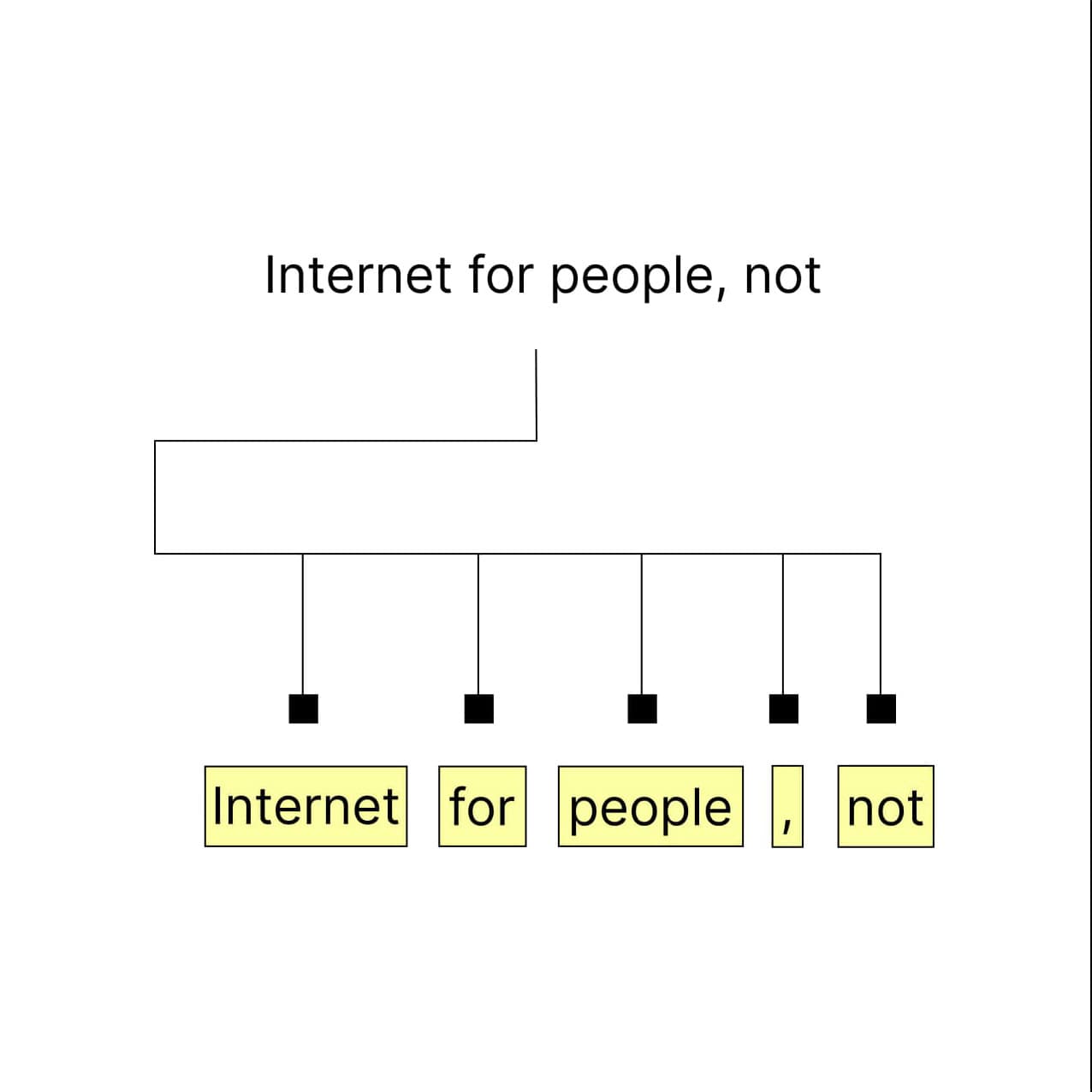
Tokenization
The LLM starts by breaking down the input text, or 'prompt', into smaller pieces known as tokens.
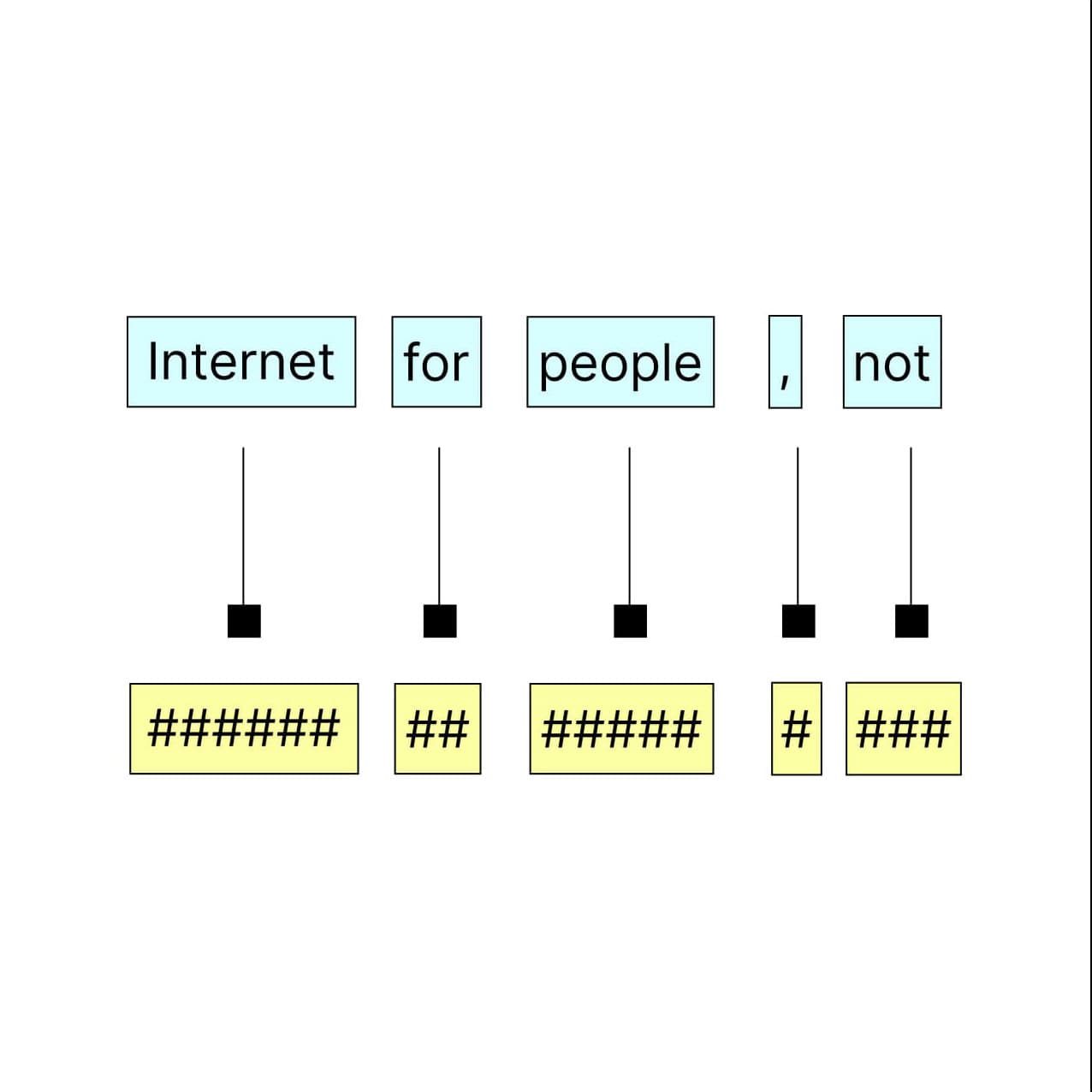
Embedding
Next, each token is converted into a numerical representation through a process called embedding.
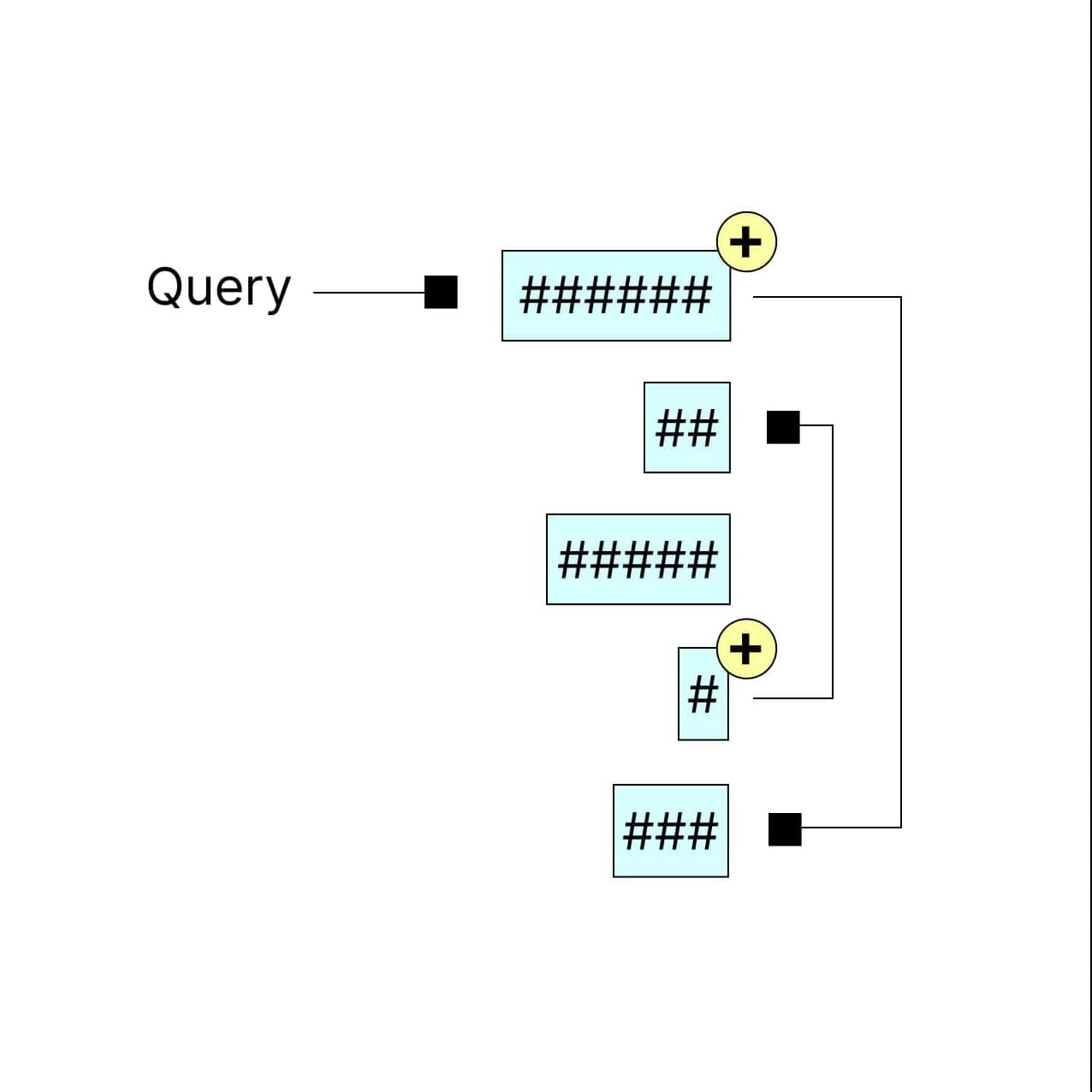
Self-attention
Now comes the real magic of the Transformer architecture: self-attention mechanisms. These allow the model to weigh the importance of different words when predicting the next word in the sentence. Self attention mechanisms allow the model to create context-aware representations of each word.
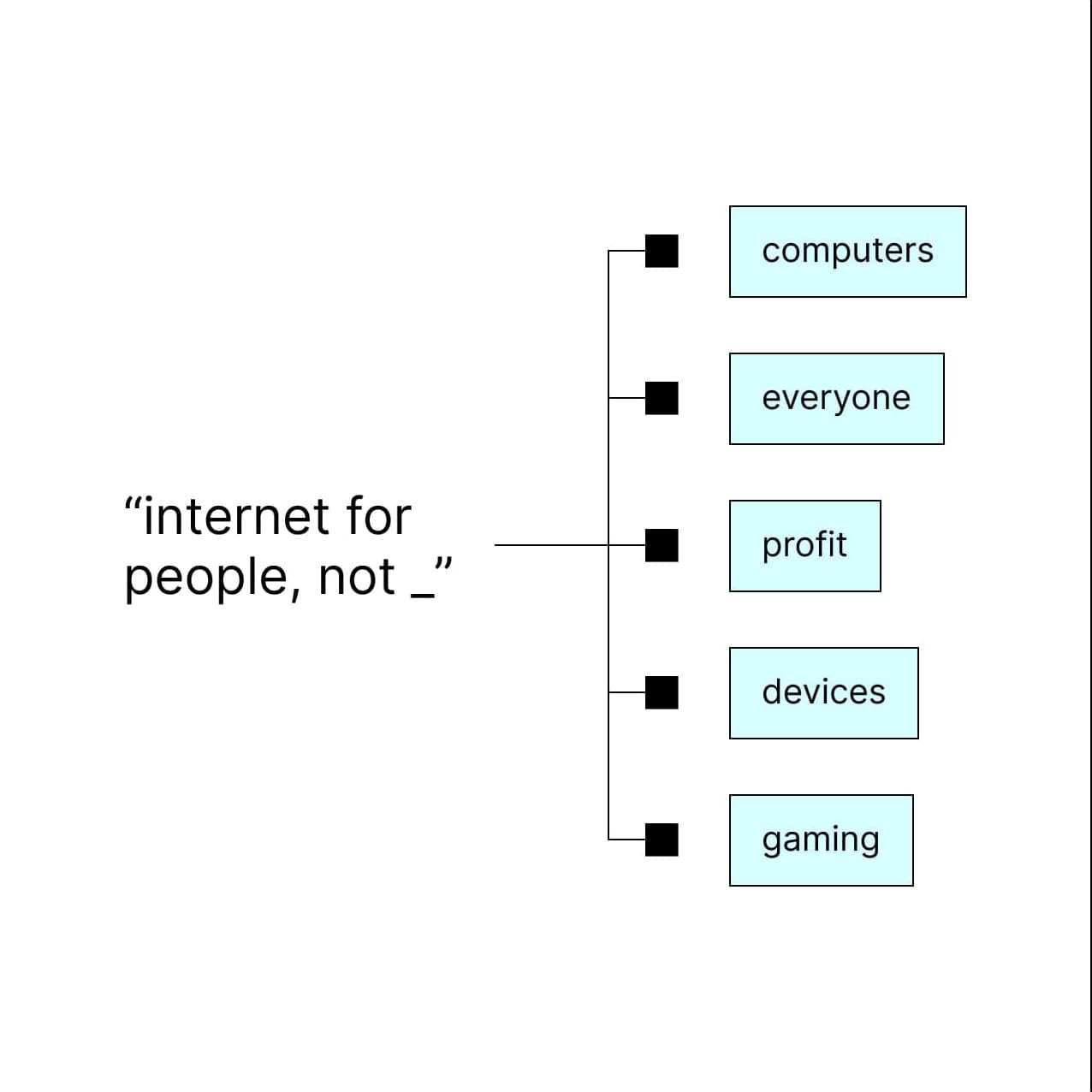
Decoding
The LLM Decoder will take the prior word sequence and contextual representation and use it to predict the next token in the sequence.
Output
Finally, the model generates new tokens, and repeats until the final response is complete.
All these steps involve complex mathematical operations and transformations. But fundamentally, what the model is doing is learning patterns in the data it was trained on, and using those patterns to generate new text that fits within the same patterns.
So, in essence, a Transformer-based LLM is a cleverly designed pattern recognition system that uses learned associations between words to generate human-like text. It's like having a scribe who has read billions of bits of content and can produce text on any topic in a style or format that mirrors the content it was trained on.
What are the pros & cons of using an LLM?
Although LLMs have made it possible for computers to process human language in ways that have been previously difficult, if not impossible, they are not without trade-offs:
Pros
Improved Token Prediction Accuracy: LLMs are trained on large amounts of human-readable data (e.g. written text, code, and audio) and rely on state-of-the-art techniques to determine patterns within those data. The size and pattern recognition techniques (e.g. Transformers) improve the accuracy of predictions over previous systems.
Efficiency: With LLMs, tasks such as language translation and chatbots can be automated, potentially freeing up time for humans to focus on more complex tasks.
Language Generation: LLMs can generate human-like language output, making them applicable for tasks such as content creation and copywriting.
Code Generation: LLMs can generate code output, making them a powerful addition to developers' toolkits.
Cons
Computational Power Requirements: Training an LLM requires significant computational power, which can be expensive and time-consuming.
Reproducing problematic training data: Because LLMs are trained on massive amounts of data, they can perpetuate biases and toxicity (like hate speech) that exist in the training data.
Lack of Transparency: The inner workings of an LLM can be difficult to understand, which makes it challenging to identify how it arrived at a particular decision or prediction.
LLM hallucinations: One of the most interesting and controversial aspects of LLMs is their ability to generate realistic language output that they have never been trained on. This phenomenon is known as LLM hallucination, and it has raised concerns about the potential misuse of these models.
What new behaviors do LLMs unlock?
Large Language Models (LLMs) have unlocked a plethora of new behaviors that were previously impossible for computers to achieve. For example, LLMs can now generate highly convincing human-like text, which has led to the development of more advanced chatbots and virtual assistants. Additionally, LLMs have revolutionized the field of natural language processing by enabling machines to understand and interpret complex human language in ways that were previously impossible. This has opened up new possibilities for automated language translation, content creation, code generation, and even sentiment analysis. With continued advancements in LLM technology, we can expect to see even more exciting developments in the near future.
When I send a Transformer-based LLM a “prompt”, what happens internally in more technical terms?
Tokenization: This is the first step in processing text data. The tokenizer converts raw text into chunks known as 'tokens'. These tokens can represent words, subwords, or even characters depending on the granularity of the tokenization process. For instance, a word-level tokenizer will convert the sentence "I love coding" into 'I', 'love', 'coding'.
Embedding: Once the text is tokenized, these tokens are transformed into dense vectors of fixed size in a high-dimensional space through the embedding layer. These embeddings capture semantic information about the words. For example, in this space, 'king' and 'queen' would be closer to each other than 'king' and 'apple'.
Positional Encoding: The encoder processes the input sequence into a context-dependent representation that captures the meaning of the text. It uses a Transformer architecture which allows it to pay varying levels of 'attention' to different parts of the input sequence at each step of the encoding process. The output of the encoder is a series of hidden states.
Encoder: The encoded input is passed through several layers (the exact number depends on the model architecture). Each layer consists of self-attention mechanisms and feed-forward neural networks. These layers allow the model to consider all parts of the input when generating each part of the output.
Decoder (if applicable): The decoder generates output text token by token based on the hidden states from the encoder. In some models like GPT-3, the decoder is essentially the entire model. It also uses a Transformer architecture and attention mechanism to focus on the relevant parts of the input.
Attention Mechanism: This is a key part of both the encoder and decoder in a Transformer. It helps the model dynamically focus on different parts of the input sequence as it processes the data. It computes a weighted sum of input values (or 'query') based on their relevance (or 'attention scores') to the current 'key' value.
Output Generation: Finally, the model generates the output text. This is done one token at a time, with the model deciding on the most likely next token based on the current state. The process continues until the model generates a termination token or reaches a preset maximum length.
Each step in this process involves complex mathematical operations and transformations. But at a high-level, the goal is to convert text into a form that the model can understand, let the model process and generate a response, and then convert that response back into human-readable text.